Technical Deepdive
This document describes the technical architecture and implementation details of SpliDT.
SpliDT Architecture
SpliDT's partitioned inference architecture, processing flow windows in two phases: (1) Feature Collection and Engineering (left) and (2) Subtree Model Prediction (right)—leveraging resource reuse (i.e., registers and match keys) via recirculation, for efficient execution within each DT partition.
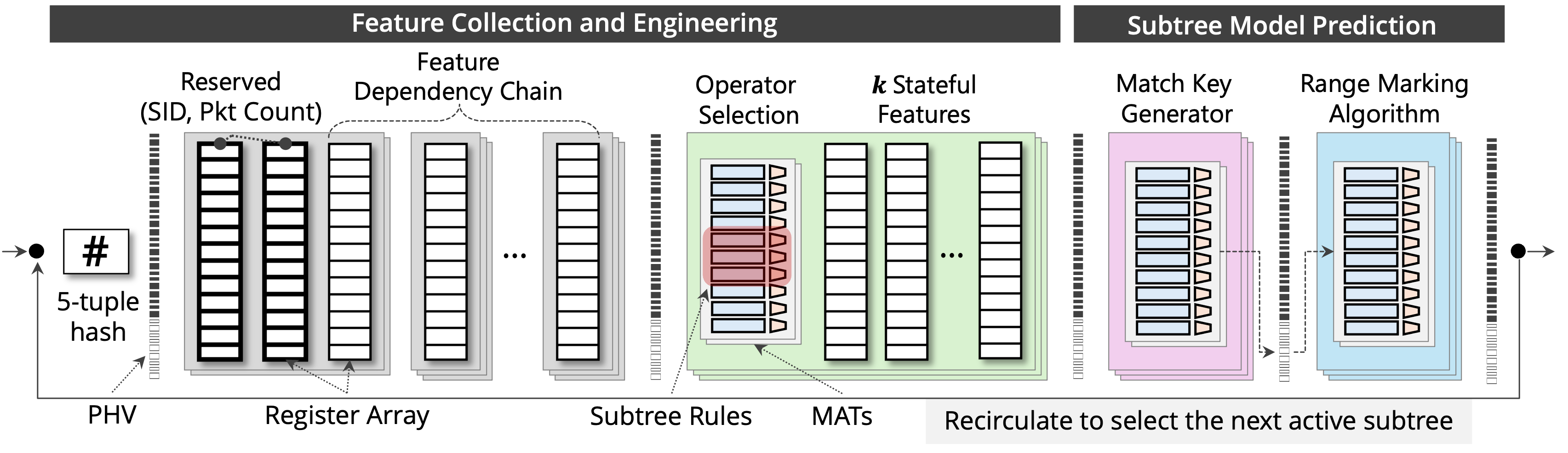
Feature Collection and Engineering
- Upon packet arrival, SpliDT hashes the packet’s 5-tuple using CRC32 to determine the register index corresponding to the flow.
- The system retrieves the subtree ID (SID) from the reserved state registers and updates per-flow counters such as packet counts.
- Stateful features required for prediction are collected using register arrays, which maintain flow-level state across packets.
- To dynamically compute subtree-specific features, SpliDT uses match-action tables (MATs) as operator selectors.
- These MATs match on the current subtree ID (SID) and apply the appropriate operator (e.g., increment counters, compute time gaps, update statistics) required for the active subtree.
- Additional match conditions (e.g., TCP flags) can be used to control when feature updates occur, enabling feature computation only on relevant packets within the flow window.
Subtree Model Prediction
- After feature collection, SpliDT executes the decision tree model using the Range Marking Algorithm.
- The first set of MATs, called match key generators, determine which stateful features are used as inputs for the current subtree model.
- Each feature value stored in metadata is mapped to a range mark, which encodes the range in which the feature lies.
- These per-feature range marks are combined with the current subtree ID (SID) to form the match key for the final classification table.
- The final MAT encodes the decision rules of the partitioned decision tree and performs classification.
- If the subtree belongs to an intermediate partition, the table outputs the next subtree ID (SID).
- If the subtree corresponds to a final partition or early-exit node, the model produces the final class label, which is sent to the controller via a digest message.
Resource Reuse via Recirculation
- After completing inference for the current subtree, SpliDT propagates the next subtree ID (SID) using packet resubmission (recirculation).
- A single packet is resubmitted with the updated SID encoded in a metadata field.
- This mechanism acts as an in-band control channel, allowing the pipeline to update the flow state without requiring external controller intervention.
- Upon resubmission, the SID register is updated and the feature registers are reset for the next flow window.
- This enables SpliDT to incrementally execute partitioned decision tree inference, evaluating one subtree at a time.